Open Data and Search Relevance
One of the interesting byproducts of the continued adoption of the Socrata platform is a constantly evolving network of open data publishers. When you have all of the world’s open data within the same platform, interesting opportunities for cross-dataset insights and connectivity become possible.
The Discovery team at Socrata has been busy building out some of the software that will allow us to begin to surface this network to our users. Our first product offering along these lines is the search engine powering the Open Data Network. As it happens, it is also the same system that backs our version 2 catalog search interface, which our customers interact with regularly when they visit their Socrata site’s browse endpoint (eg. data.seattle.gov/browse) to update, analyze, and visualize their data.
We have spent some time recently trying to improve this core piece of technology both in terms of performance as well as accuracy and relevance. In this blog post, I will discuss how we use crowdsourcing to collect relevance judgments to measure the quality of the search results in our catalog search engine. The high-level steps are as follows:
- sample a set of queries from query logs to serve as a measurement set
- given a particular version of the search engine, collect results for each query in the measurement set
- assign a relevance judgment to each (query, result) pair
- compute relevance metrics
Building an amazing search experience isn’t easy. Google has set the standard; as users, we expect our search results instantaneously, and we expect them to be highly relevant. How does Google do it so well? There has been some recent discussion about Google’s use of a new AI system as an additional signal in their search result ranking model. It has been standard practice in the industry for some time to have a machine learned ranking model – often an artificial neural network – that incorporates a variety of signals. But rather than focus on the internals of an open dataset search engine, I want to talk about how to measure relevance.
I have long been a fan of the following quote: “you cannot improve what you cannot measure”. The first step in improving any search engine is being able to compute a metric that captures the quality of results. Precision and recall are often thought of as the de facto metrics for Information Retrieval systems. But there are a couple of notable shortcomings of precision and recall (and the closely related F-measure, which combines precision and recall into a single measure). Firstly, recall is generally difficult to measure within the context of search engine because it requires knowing and judging the relevance of all possible results for a particular query. In some cases, the cardinality of that result set could be on the order of hundreds of thousands. Additionally, neither precision, recall, nor F-measure take into account the ordering of results.
As users, we expect the most relevant results to be at the top of the search engine results page (SERP). We rarely even look beyond the first page. According to this study by the folks at Moz, about 71% of Google searches result in a click on the first page and the first 5 results account for 68% of all clicks. In Socrata’s catalog search engine, only 6% of users click past the first page. Normalized discounted cumulative gain (NDCG) has seen widespread adoption as a core metric in the search industry precisely because it accounts for our expectation as users that the best results be at the top of the SERP (and that results further down the list contribute less to our perception of quality).
So how do we compute NDCG? Cumulative gain is a measure we apply to an individual query based on the results in our results list (usually capped at position 5 or 10). To compute it, we must assign a relevance score to each result in our results list, and then we simply sum relevance scores at each position.
where
What makes NDCG effective is its discount term. Discounted cumulative gain is a simple variation on the CG function defined above:
where
The idea here is that we have a discount function in the denominator that is a monotonically increasing function of position. Thus, the denominator increases as we go further down the results list, meaning that each result contributes less to the overall sum of scores. (Strictly speaking, we use the second variant described on the Wikipedia page for NDCG .)
Finally, the score is “normalized” (the “N” in “NDCG”). DCG is a measure that we compute for each query, but not all queries are created equal. For some queries, a search engine may have 10 or more highly relevant results. For other queries, there may be far fewer or none at all. In order to be able to compare across queries (or average across them to capture the search engine’s performance across an entire query set), we need them all to be on the same scale. To do this, we normalize the DCG of each query by the DCG of the best possible ordering of the same results.
where is the DCG applied to the ideal set of results for a given query.
In practice, we collect more and more judgments for a particular query-result pair over time as we compare more and more variants of our system. When we go to normalize our DCG score, we take as ideals the best possible ordering of the best results from the history of all judged query-result pairs.
Let’s consider an example. We have a query “crime incidents” and the top 5 results are judged to be “perfect”, “irrelevant”, “relevant”, “loosely relevant”, and “loosely relevant” respectively (represented on our numeric scale as 3, 0, 2, 1, 1). A corresponding ideal ordering would be 3, 2, 1, 1, 0. And we could compute NDCG like so:
from math import log
def dcg(judgments): # the +2 in the discount term because of 0-based indexing
return sum([x / log(i + 2, 2) for (i, x) in enumerate(judgments)])
def ndcg(judgments):
ideal_dcg = dcg(sorted(judgments, reverse=True))
return (dcg(judgments) / ideal_dcg) if ideal_dcg else 0.0
print ndcg([3, 0, 2, 1, 1])
0.927779663887
In order to attach a metric to our search engine’s performance, we need relevance judgments for each query-result pair. How do we collect these measurements? Well, the most obvious way is to hire an army of data annotators and to have them assign a judgment to each query-result pair. As it turns out, this is one of the tasks that workers in Microsoft’s Human Relevance System and Google’s Quality Rater program are asked to do.
In the case of Microsoft and Google, the people hired to make these relevance judgments are trained. Certainly, part of the motivation for this is that it allows Google and Microsoft to craft a much more nuanced task. This allows them to incorporate more than just search term relevance into their judgments (freshness, authority, etc.). In contrast, there are a few companies that offer crowdsourcing services like Amazon Mechanical Turk and CrowdFlower with dynamic workforces consisting of untrained workers, which is typically much more cost effective than training and managing your own team of annotators. One key observation here is that the level of training required is very much task-dependent. For Socrata, the task of assigning relevance judgments as we have framed it, while somewhat subjective and occasionally nuanced, is relatively straightforward, and thus, a workforce of untrained workers is sufficient (for now). We track the quality of the annotations that we collect by comparing crowdsourced judgments on a sample of data to corresponding judgments assigned by in-house experts.
There are a few different dimensions to consider when designing our relevance task. The first is the arity of the task. Do you present the annotator with a single result (pointwise), a pair of results (pairwise), or a list of results (listwise)? The next dimension to think about is the type of judgment. Should you collect binary relevance labels, scalar relevance judgments, or should you simply ask the assessor to provide an ordering between results in a list? There are pros and cons to each of these approaches, which I’ve enumerated in the table below. Ultimately, we have adopted the pointwise approach, with absolute, scalar judgments, which has a few advantages. The first is its simplicity. As a simpler task, it can be completed more quickly and more reliably by annotators. But also, it’s the most cost effective approach because it requires the fewest judgments. A judgment made about a query-result pair in isolation is absolute and reusable; once a particular QRP has been judged, it never has to be judged again. Given the task’s inherent subjectivity, we opted for scalar judgments (rather than binary judgments) since they allow us to to capture as much information as possible at a reasonable cost.
| Listwise | |
|---|---|
| Pros | Cons |
|
|
| Pairwise | |
| Pros | Cons |
|
|
| Pointwise | |
| Pros | Cons |
|
|
[†] Carterette et al set out to show that pairwise judgments are the simplest for assessors. They show that relevance judgments typically obey transitivity, which means that the full set of n2 pairwise judgments is not actually required. For our part, we have trouble justifying the complexity involved in building such a system given the marginal gain in task simplicity.
Our typical task looks as follows:
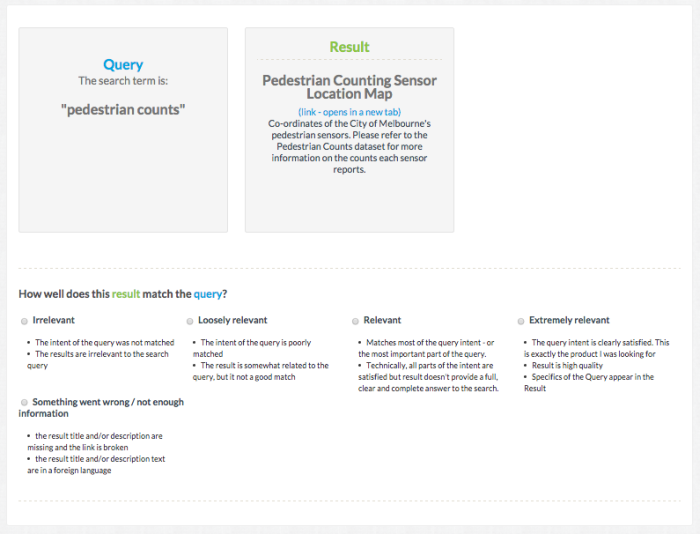
Depending on the platform (presently, we’re using CrowdFlower), we can collect job output programmatically via API as JSON or from a GUI as a CSV. We persist query sets and judgments in a Postgres database with an eye towards reproducibility, while also ensuring that we never unintentionally re-submit previously judged pairs.
One neat feature of CrowdFlower is its quality control mechanism. We, the task designers, are prompted to enter “gold” data, which is used to a) avoid collecting bad data from scammers, and b) help instruct workers, and c) weight the judgments provided by workers according to their trustworthiness. Getting multiple judgments for each QRP allows us to average out the results, thus getting a more reliable signal than had each QRP been judged only once. Looking at the variance of the judgments provided by our workers, we can identify particularly difficult and nuanced pairs, which may serve as valuable test data for its instructional value. Additionally, including these high-variance QRPs as test data helps us to better quantify the quality of work that we’re getting from each annotator.
At this point, we have collected judgments for about 8000 query-result pairs. This is just a start, but it’s enough for us to start doing some interesting things. Most importantly, it has allowed us to directly compare our catalog search systems – old vs. new – in terms of relevance. And the results are encouraging; in addition to the obvious increase in performance, and the improvements to the UI, the new system produces more relevant results than the old. We have created a Python package to support this process that is publicly available on Github. Any feedback is much appreciated.
Crowdsourced relevance judgments only tell part of the story; they are a proxy for how real users perceive the quality of our search results. In future posts, we will write in more detail about collecting usage data and computing online metrics such as Click-Through Rate, and subsequently using click data to train a machine learned ranking model.
References
- “Google Organic Click-through Rates in 2014”, Philip Petrescu
- “Measuring Search Relevance”, Hugh Williams
- “Yes, Bing Has Human Search Quality Raters & Here’s How They Judge Web Pages”, Matt McGee
- Learning to rank: from pairwise approach to listwise approach, Cao, Qin, Liu et al.
- Here or There: Preference Judgments for Relevance