Scrubbing data with Python
There’s an awesome Python package called Scrubadub that can can help you remove personally identifiable information from text data. This is a great step to take before publishing a dataset that may contain PII, in order to prevent inadvertent disclosure.
In this example, we’ll clean up some CSV data using Scrubadub, in order to prep it for loading in Socrata:
- First we’ll load a local CSV it into a dataframe with Pandas,
- Then we’ll remove names using Scrubadub,
- And finally write it to a CSV that can be loaded using DataSync.
Prerequisites
Before you start, make sure you have the following installed on your machine:
Loading your CSV with Pandas
Create a dataframe from your local CSV file with Pandas:
import pandas as pd
df = pd.read_csv('~/Dallas_Police_Officer-Involved_Shootings.csv')
df.head(n=5)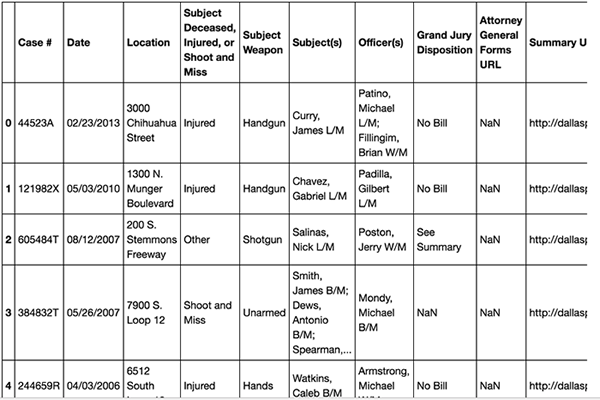
Remove names using Scrubadub
Scrubadub is a simple package that will look for names and other identifying information, like email addresses, SSNs, and phone numbers.
import scrubadub
scrub = lambda x: scrubadub.clean(x.decode('utf-8'), replace_with='identifier')
df['Officer(s)'] = df['Officer(s)'].apply(scrub)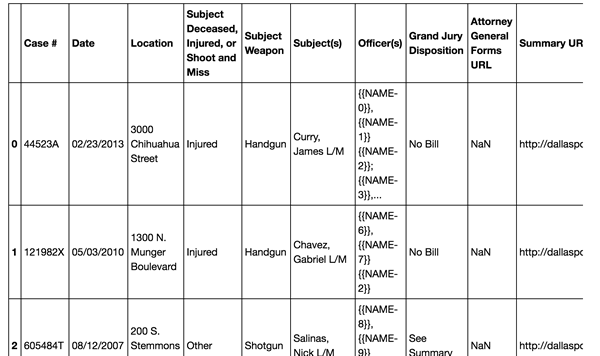
Data cleansing is a serious topic and you should always work with your privacy or policy officers within your organization to make sure you are taking the correct steps to protect privacy.
Write cleansed data back to CSV
Finally, we’ll write our cleansed records back out to CSV:
df.to_csv("~/Dallas_Police_Officer-Involved_Shootings.csv", encoding='utf-8', index = False)Once you’re done, the cleaned data file can be used to update a dataset via DataSync. For more information, see its detailed documentation