Natural Language Processing of Consumer Complaint Narratives with SODAPy and Algorithmia
Today, we’re going to do some rapid natural language processing using a combination of Socrata’s “SODAPy” library and Algorithmia’s “Social Sentiment Analysis API”. Let’s get started!
- SODAPy is a community-created set of Python bindings for the Socrata Open Data APIs which we love to use and share with others! It has become so popular among our data publishers and consumers that we at Socrata recently forked it and have started adding additional functionality.
- Algorithmia is an API marketplace which provides automated access to important functionality that developers (previously) had to build on their own. It offers the virtual sharing of powerful functionality with just simple API calls.
Together, SODAPy and Algorithmia offer us a great opportunity to do some quick social sentiment analysis on one of my favorite datasets, the U.S. Consumer Financial Protection Bureau’s incredible Consumer Complaints Database. This dataset includes thousands of real narrative complaints about financial products and services submitted by consumers to the U.S. CFPB. And since I’m interested in doing some Natural Language Processing, the filtered view CFPB has created for their full-text narratives is an excellent test case. By using Algorithmia’s Social Sentiment Analysis API, we can quickly get a sense of how positive or negative these narratives really are.
Although this data is all "complaint narratives", perhaps we may be surprised by how positive or negative the text really is. What do you think?
We’ll begin by first loading up our needed modules and libraries:
from userConfig import socrataClient, algoKey
import Algorithmia
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
%matplotlib notebook # Show the plots in the iPython notebook
And here are our user configurations for both SODAPy and Algorithmia:
# Setting up auth/interface to Socrata
from sodapy import Socrata
socrataClient = Socrata("data.consumerfinance.gov", "myAppToken",
username="user.name@domain.com",
password="passw0rd!")
# Algorithmia App Token
algoKey = 'algoAppToken'
Running our analysis on a single record
As a quick test, let’s make a one-record request (limit=1) to the CFPB dataset using SODAPy. Observe the straightforward syntax, my specifying of “JSON”-formatted results, and the dataset ID which denotes this view.
try:
response = socrataClient.get("nsyy-je5y", content_type="json",limit=1)
print(response)
except:
print('Got an error code')
data = response[0]
The results:
[{'zip_code': '273XX', 'complaint_id': '1896418', 'issue': 'Disclosure verification of debt', 'company': 'CFS2, Inc.', 'submitted_via': 'Web', 'date_received': '2016-04-26T04:31:16', 'complaint_what_happened': 'I disputed a CFS2 trade-line on XXXX of my credit reports. These were initially disputed on XXXX XXXX, XXXX to XXXX via certified mail and XXXX on XXXX XXXX, XXXX. Each of these were verified by CFS2. \n\nI subsequently received letters from CFS2 dated XXXX XXXX, XXXX and XXXX XXXX, XXXX stating they did not have the necessary information to verify my account and would need 60-90 days to do this. I disputed this trade-line again with both XXXX ( XXXX XXXX, XXXX ) & XXXX ( XXXX XXXX, XXXX ) and CFS2 verified both accounts again. \n', 'sub_issue': 'Not given enough info to verify debt', 'state': 'NC', 'company_response': 'Closed with explanation', 'consumer_consent_provided': 'Consent provided', 'product': 'Debt collection', 'consumer_disputed': 'No', 'date_sent_to_company': '2016-04-26T04:31:17', 'timely': 'Yes', 'company_public_response': 'Company believes it acted appropriately as authorized by contract or law', 'sub_product': 'Credit card'}]
This is a great example of how easy it is to use SODAPy - just specify the dataset ID, the desired data format, and whatever filters and limits you’d like to apply. With that full row, let’s now extract just the narrative text and shoot it over to Algorithmia’s Social Sentiment Analysis API. Our expected results, as the API documentation describes, should be a set of scores which evaluate a text-string’s positivity/negativity.
Specifically:
complaintText = data["complaint_what_happened"]
try:
algoClient = Algorithmia.client(algoKey).algo('nlp/SocialSentimentAnalysis/0.1.2')
daInput = {"sentence":complaintText}
AlgoResponse = algoClient.pipe(daInput)
print(AlgoResponse)
except:
print("An error occurred")
And the resulting scores:
AlgoResponse(result=[{'neutral': 0.897, 'positive': 0.027, 'compound': -0.5574, 'sentence': 'I disputed a CFS2 trade-line on XXXX of my credit reports. These were initially disputed on XXXX XXXX, XXXX to XXXX via certified mail and XXXX on XXXX XXXX, XXXX. Each of these were verified by CFS2. \n\nI subsequently received letters from CFS2 dated XXXX XXXX, XXXX and XXXX XXXX, XXXX stating they did not have the necessary information to verify my account and would need 60-90 days to do this. I disputed this trade-line again with both XXXX ( XXXX XXXX, XXXX ) & XXXX ( XXXX XXXX, XXXX ) and CFS2 verified both accounts again. \n', 'negative': 0.076}], metadata=Metadata(content_type='json', duration=0.127483706, stdout=None))
Perfect. And finally, we extract just the compound sentiment score which applies to our chosen narrative:
compoundScore = AlgoResponse.result[0]['compound']
print(compoundScore)
-0.5574
Other querying with SODAPy
Before we run this analysis at scale, a couple of words on SODAPy. Above, we specified limit=1 to return a single row from the dataset. But we could also have used different query parameters to GET just the rows we need. For instance, for all complaints submitted against Equifax:
response = socrataClient.get("nsyy-je5y", content_type="json", company = "Equifax")
or to get complaints submitted since the beginning of 2015:
response = socrataClient.get("nsyy-je5y", content_type="json", limit=1, where="date_received > '2015-01-01'")
These and other possibilities are documented in the SODAPy documentation or specified in our documentation on specific SoQL keywords, and collectively they make the SODAPy client library an easy-to-use alternative to using Python’s Requests libraries for building queries separately.
Running the analysis at scale
Now let’s do this for real, and at scale! We will (1) request data via SODAPy, (2) POST the result set to the Social Sentiment Analysis API, and (3) visualize the compound scores. We can run our analysis on all records since the start of 2016:
# Requesting data from CFPB via SODAPy
try:
response = socrataClient.get("nsyy-je5y", content_type="json",where="date_received>'2016-01-01'")
print("Response received")
except:
print('Got an error code')
# Building a list of sentences to send to Algorithmia's Social Sentiment API
sentList = []
for num in range(0,len(response)):
complaintText = response[num]["complaint_what_happened"]
sentList.append(complaintText)
# Send list of complaints to Algorithmia for scoring
algoClient = Algorithmia.client(algoKey).algo('nlp/SocialSentimentAnalysis/0.1.2')
daInput = {"sentenceList":sentList}
AlgoResponse = algoClient.pipe(daInput)
print("AlgoResponse received")
# Building our list of scores for eventual visualization
scoreList = []
for x in range(0,len(response)):
daScore = AlgoResponse.result[x]["compound"]
scoreList.append(daScore)
At this point, we have our list of sentiment scores for all requested records, values which range between -1 and 1. But wouldn’t it be interesting to see how these scores are distributed? It sure would!
Visualizing the Sentiment Scores
Let’s create a quick histogram of the sentiment scores for all records we pulled (since the beginning of 2016):
# Using the Seaborn statistical data visualization library, based on matplotlib
sns.distplot(scoreList, bins=10, axlabel = "Overall Score Distribution")
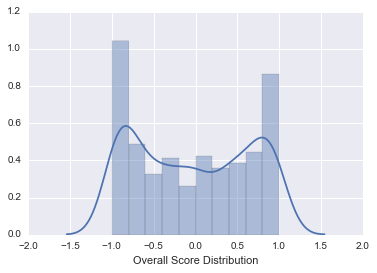
Scores across all 2016 complaint narratives seem to be weighted towards both ‘extremes’, with most complaints receiving a ‘strong negative’ (between -0.8 and -1.0) sentiment score. This isn’t terribly surprising given that the narrative content is a genuine complaint.
If we run this process again but restrict our results to just complaints submitted against the company and credit reporting agency Equifax (the company which has received the most complaints across the full CFPB dataset), we receive the following distribution:
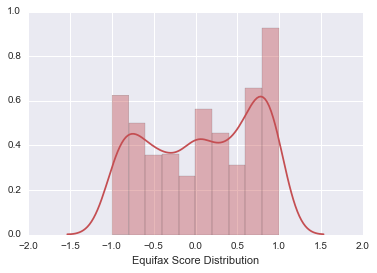
Surprisingly, this graph shows that narratives seem to be positively weighted. And when compared to an identical analysis run on complaints against Bank of America, the difference is even more stark:
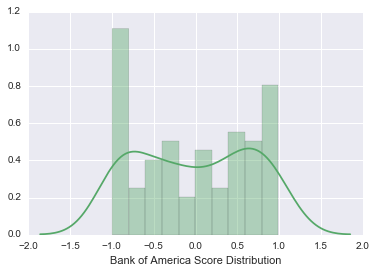
The negativity against BoA is the highest we’ve seen! Although we won’t do a deeper investigation here, perhaps this is because BofA handles a higher proportion of their business in a category which tends to receive more negative complaints, like mortgages…or possibly something else.
Thanks and Closing
That’s all for our quick-and-dirty natural language processing of CFPB Consumer Complaint Narratives! Happy SODAPy-ing!
The full code for this example is available here.