Import Translations
Heads Up! The Import API is a legacy API that is not actively maintained. If you are not already using this API, we recommend against implementing it in a new project.
Check out our Dataset Management API, instead!
Import translations are essentially a way to transform data as it’s being imported, before the importer itself sees and interprets your data. If, say, you have a column in your output that has some non-importable numbers (eg. “USD 24.50”), you can use a translation to clean up that data to just a number so that the importer will read it correctly. Or, say you have multiple columns (eg First Name, Last Name) that you’d like to combine into one in your dataset; you can use a translation to do that, too.
How Translations Work
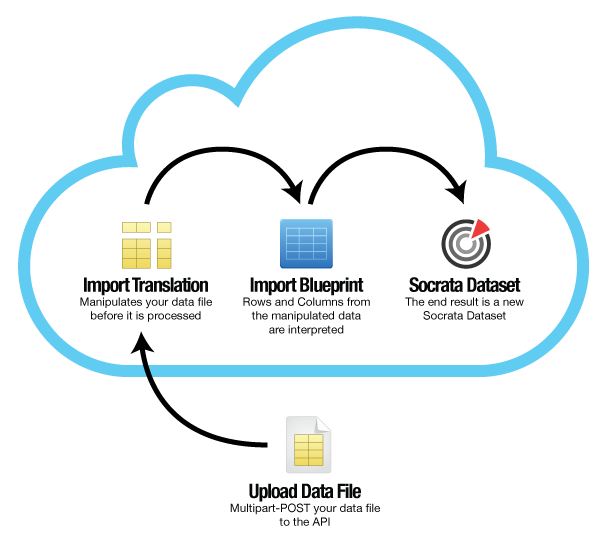
First, if you haven’t already, please read over the import process document, and make sure you understand the workflow; in particular the section about import blueprints.
Now that you know how importing works, we can talk about how and where translations fit into the import process. For that, we have this handy chart on the right.
As you can see here, translations are applied to the raw data in your source file before the import blueprint tells the importer how to import your columns. This means that should you use a translations, your import blueprint should reflect the final, transformed set of columns you wish to import, not the raw set of columns in your file.
How to Use Translations
Translations are written in JavaScript.
A translation is very simply a JavaScript array that operates on each row in your source data file, and represents what the row should look like to the importer. As a convenience, we populate a magic variable for each column in your source dataset; these are simply colN, where N is a 1-indexed. So, col1 would be the value in the first cell of the row, col2 would be the value of the second cell, and so on.
Thus, you can imagine that the default translation (if you didn’t give us one at all) for a five-column dataset would look something like this:
[col1, col2, col3, col4, col5]No matter what your original document looks like, note that each column variable is given to you as a JavaScript String. And, no matter what your translation outputs and what type your final column is supposed to be, the importer will accept a String right back.
Okay – Let’s Have Some Fun
Let’s start with something simple: say that you want to change the order in which your columns are imported; your dataset has columns first_name, last_name, amount_due. We want the last name to come first in the imported dataset. We’ll want to supply this, then, as our translation:
[col2, col1, col3]And something like this as our import blueprint:
{
"columns" : [{
"name" : "Last Name",
"datatype" : "text"
}, {
"name" : "First Name",
"datatype" : "text"
}, {
"name" : "Amount Due",
"datatype" : "money"
}],
"skip" : 1
}That’s pretty simple. Now, say instead that you want to combine the names into one field, formatted as last_name, first_name. This would be our translation, then:
[col2 + ', ' + col1, col3]And the blueprint:
{
"columns" : [ {
"name" : "Name",
"datatype" : "text"
}, {
"name" : "Amount Due",
"datatype" : "money"
} ],
"skip" : 1
}I think you get the idea on how blueprints work with translations, so I’m going to stop providing examples of those now.
One more easy example for the road; let’s say that I want to import a location directly into a native location column so that my users can create maps based on it, but in my source file the data is spread across an street address, a latitude, and a longitude column, in columns 1, 2, and 3, respectively. I have 3 other columns after that that I’m not worried about touching. For example, the Location datatype expects a location of the form [address, ][city, ][state, ][zip, ][(lat, long)]. All of my points are in the City of Seattle, so I can fill that in.
[col1 + ', Seattle, WA, (' + col2 + ', ' + col3 + ')', col4, col5, col6]Transforming the Data Itself
So far, we’ve just been mixing and matching our data. What if we want to change an actual data value? Here, we can take advantage of the fact that we have access to the JavaScript standard library, and that we’ve been given a JavaScript string, and go to town.
Let’s start with an easy one: col1 in this dataset has a bunch of 3-letter codes, but they’re inconsistently capitalized. Let’s make that right.
[col1.toUpperCase(), col2, col3]Here, col2 are a bunch of currency values, but they’re in a format that the importer won’t accept. They all look like USD 24.50. Let’s make them right.
[col1, col2.replace(/^USD /, ''), col3]And lastly, here I have a column col3 that contains both First and Last name, but I want to split them out in my dataset.
[col1, col2, col3.split(' ')[0], col3.split(' ')[1]]The Socrata Translations Library
For your convenience, we’ve provided a number of translation functions that are commonly used. You can call these functions from anywhere in your code.
upper(string)- “UPPERCASES” a given stringlower(string)- “lowercases” a given stringtitle(string)- “Title Cases” a given stringtrim(string)- This will trim whitespace from the beginning and the end of the string you pass into it.slice(string, start, end)- This function takes a string, a zero-indexed start position, and a zero-indexed end position. It will pull out the section of the string indicated by your range, trim it, and give the result to you. It’s very useful for dealing with fixed-width data files.chain(function[, function, ...])-chaintakes a series of one-argument functions (such as most of the Socrata library functions listed above), and chains them into a function that calls them in succession. So, to trim, then uppercase the value incol3, one would do: chain(trim, uppercase)(col3)
Limitations
Of course, you can’t run hog wild with this. We have some limits on what you’re allowed to do with import translations:
- Operations cannot run longer than a couple of seconds. This is to keep imports from taking too long and slowing down other people’s pending import jobs. If any particular row takes too long to import, it is ignored and a warning is added to the final dataset indicating the problem.
- You are limited to a secure sandbox. Though we run your Javascript out of the context of a web browser, we don’t allow access to any of the extra APIs this generally implies. No filesystem access for you!
- If something goes wrong, the row is thrown out, and a warning is added to the final dataset.
- On the other hand, the importer will stop producing warnings if you have too many. It will indicate when this occurs.