Elixir in production, an open data tale
Elixir in production, an open data tale
The problem
The job of the Data Pipeline team is to build and maintain software to seamlessly get data into our platform.
Socrata has had, for a long time, a wizard which would parse certain files, provide a few formatting options, and allow the user to import the data into the Socrata platform.
This process had a few major issues. It was an all or nothing deal - either your data had issues and it would fail to import, or it was perfectly clean. It also didn’t provide any feedback on what the status of anything was; you just saw an indefinite spinner until you didn’t anymore. To make matters worse, if there was an issue, you often got an error message that didn’t tell you how to fix your source data.
When we set out to make that experience better we had one major goal: be transparent about what’s happening with the data. Every step has information that is potentially actionable, and we should surface that information as soon as we know it. We wanted to front-load all of the actionable information, so the user can upload their file, make their changes and walk away before the file is even done uploading. We also want to provide a quick retry cycle if the user uploads something and realizes it’s wrong. This allows them to go back to the data owner or source and fix it quickly.
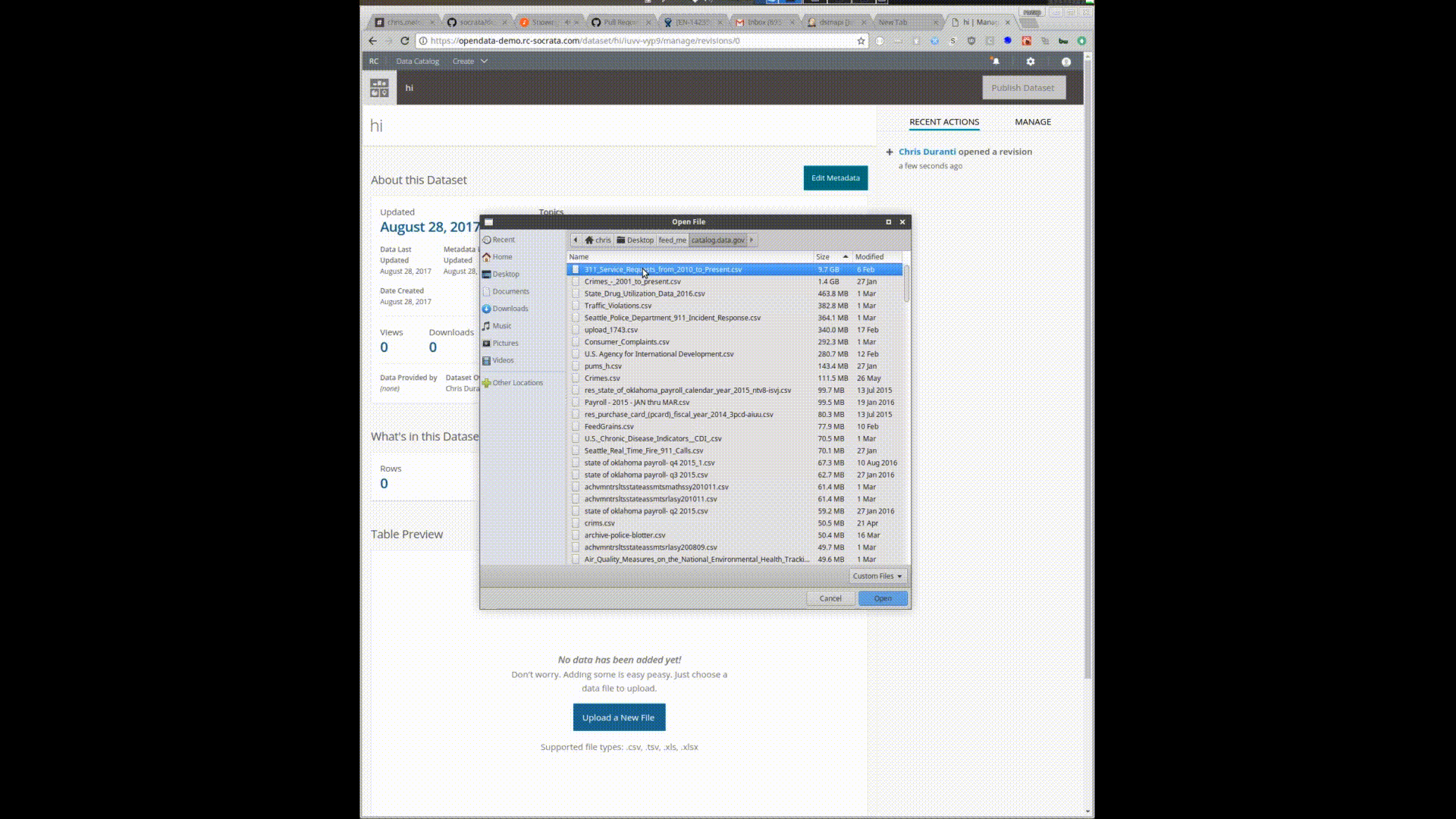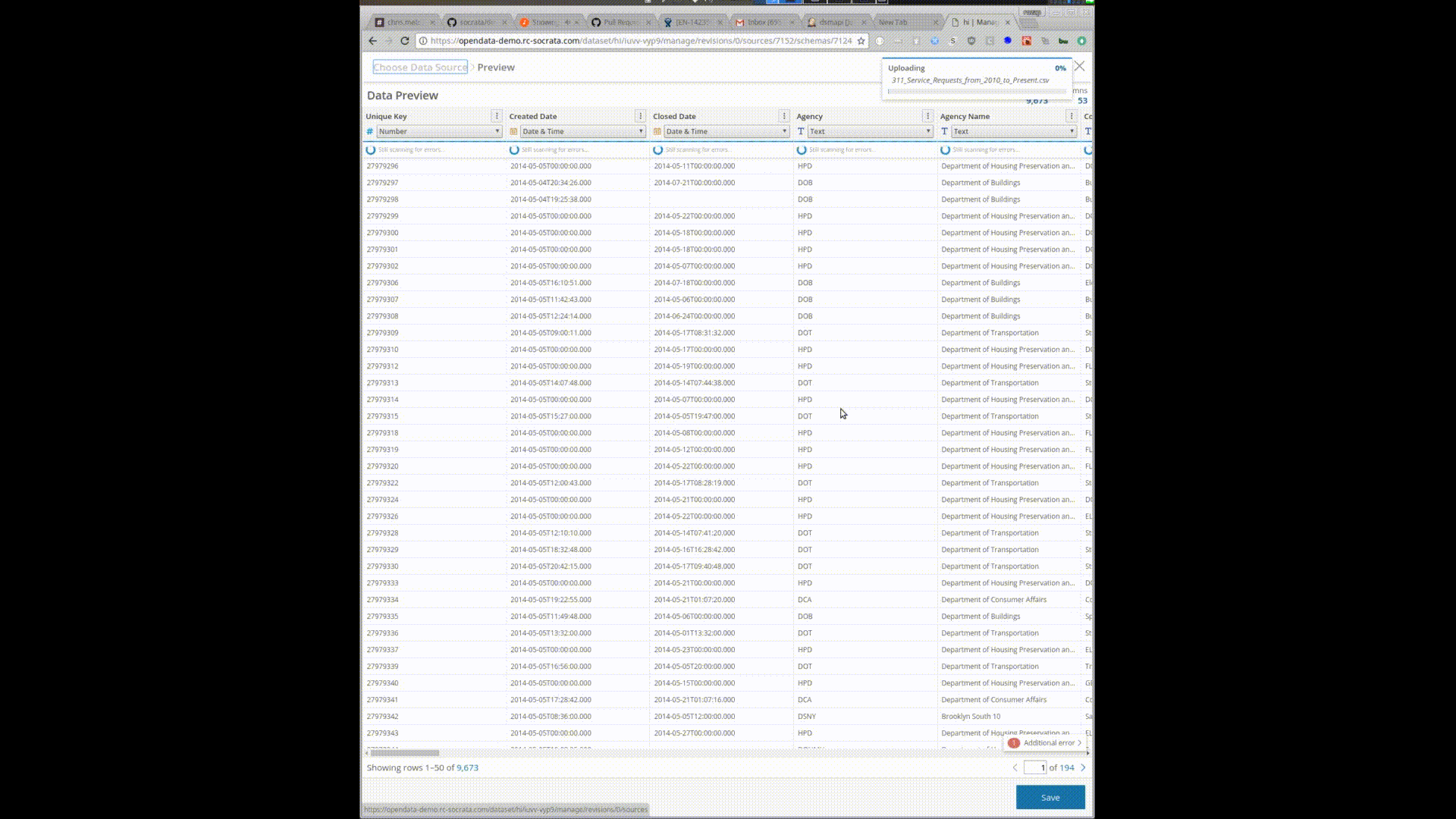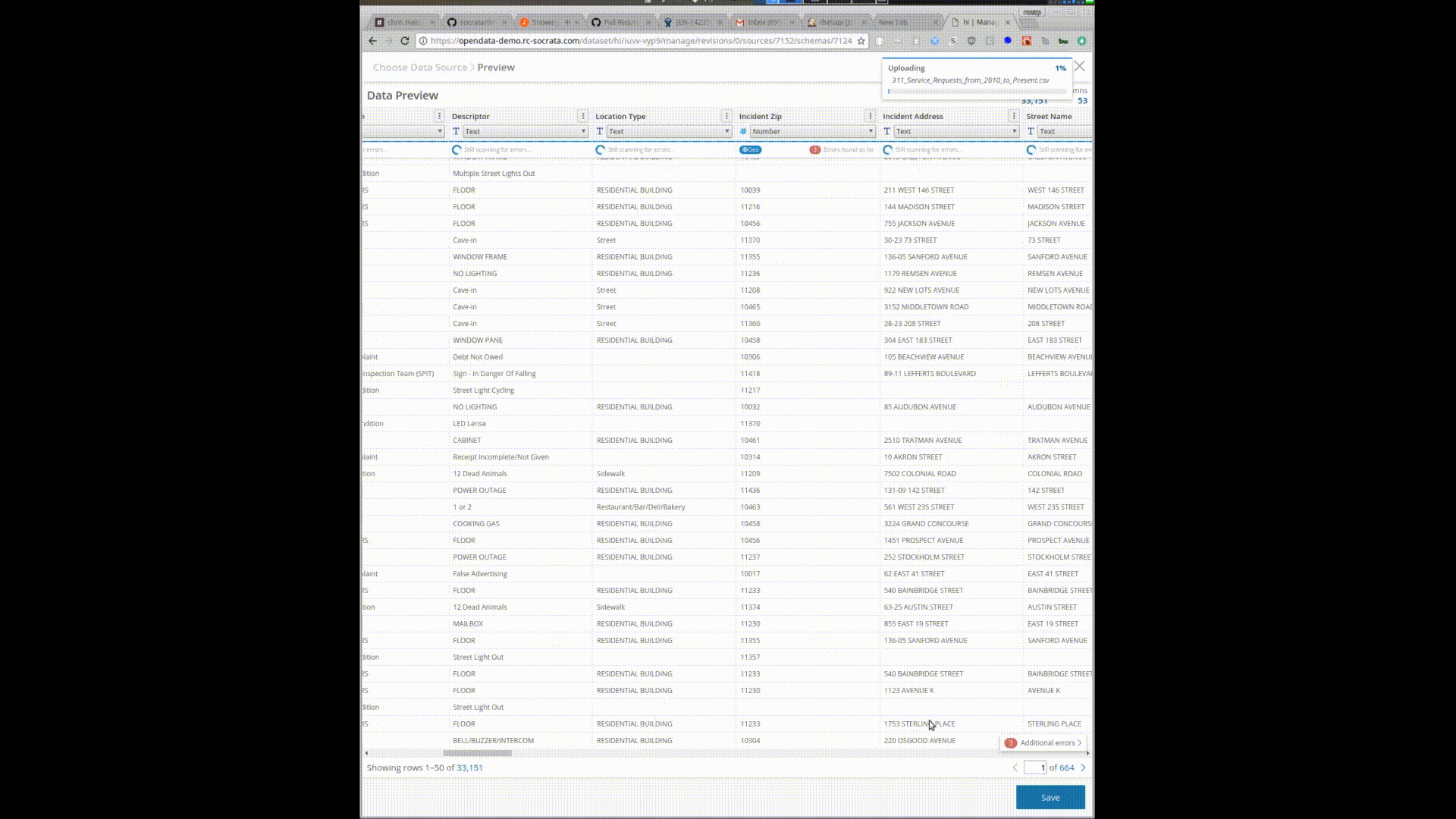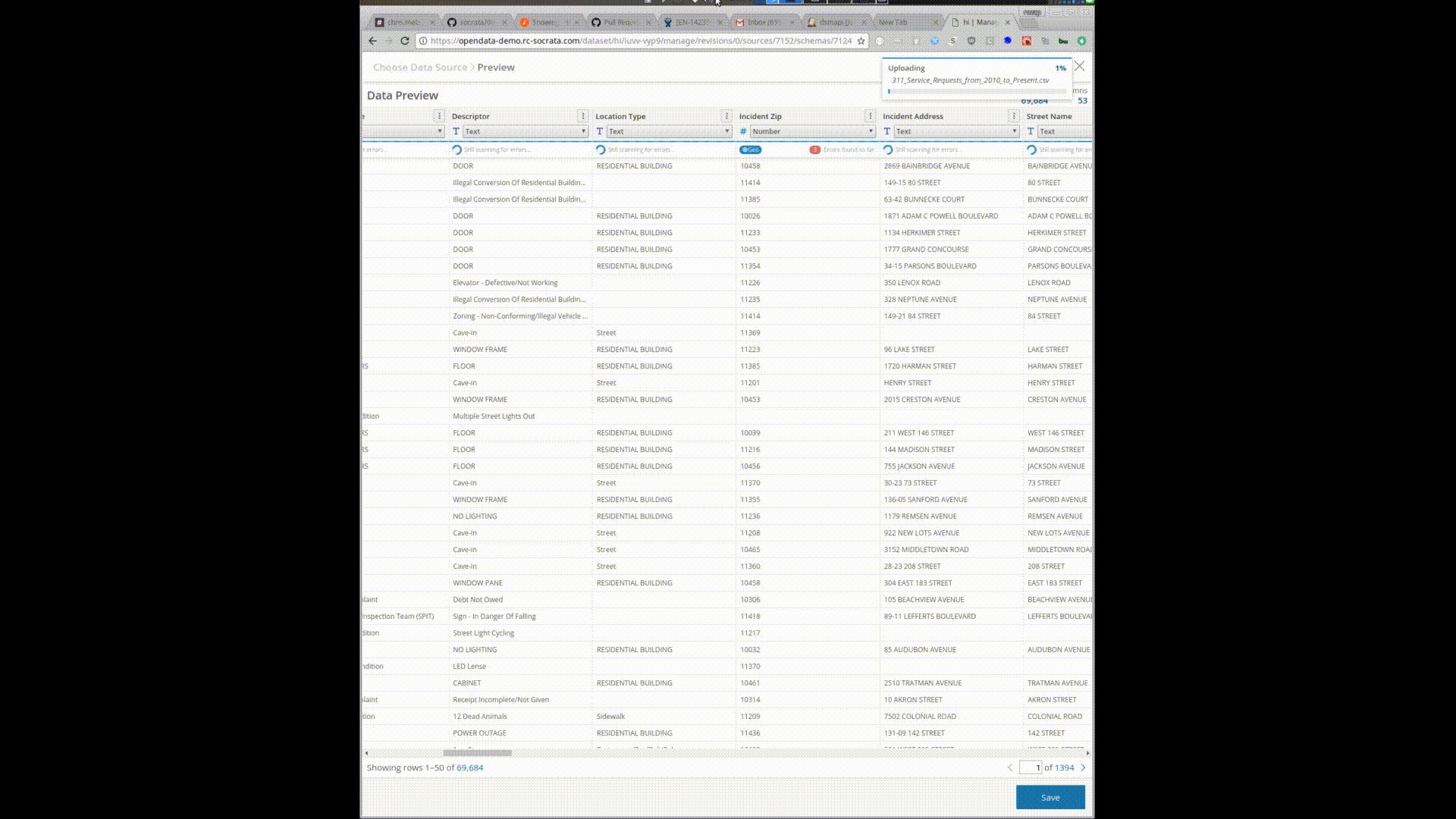
Uploading this 10gb/28 million row file gives you a preview and the ability to start interacting and transforming the data before it is uploaded
We also had an internal goal, which was to run our service(s) sustainably with a relatively small team (about 4 backend engineers, who also have other jobs to do). Our engineering team had been adopting a microservices model, which, despite all the Medium thinkpieces extolling the virtues, had failed to deliver us to engineering nirvana as we had hoped. With a small number of human engineers, and a large number of services, context switching between them became challenging. Moreover, due to the small size of our engineering organization, we had no dedicated team working on tooling, which led to duplicated effort across teams who were all chartered to deliver customer value, not engineering value.
What we built
Given the UX problems, the engineering problems, and the goal, we settled on Elixir and Phoenix as the tools to make this thing work. There are plenty of other posts that describe why Elixir is interesting, but in short, it was the only tool that would allow us to accomplish the real time feedback we wanted in a single package. Elixir and Erlang* also provide primitives for building and running distributed systems that can’t be beat (at the moment), and given that we were going to be doing computation across the whole cluster in parallel, it seemed like the right tool for the job.
The core of the data pipeline service is really an interpreter, which interprets the same language used for querying data, called SoQL (Socrata Query Language). SoQL looks a lot like SQL, but it’s simplified for the use case we see a lot at Socrata. We also needed an API around said interpreter, for accepting data and allowing the user to manipulate it, which is where Phoenix came in.
In our data pipeline service, we implement a different set of functions that are required to transform data. An example would be the following
geocode(address, city, state, zip)
This, given columns in your source file called adresss, city, state, and zip, will geocode the values and make a new column, which can then be imported alongside the rest of your data.
Obviously faster is better, so all the execution happens with as much parallelism as we can get out of the cluster. This is where Elixir really shines. Coordinating all that state across the cluster would have been tricky, but in Elixir, it’s trivial to assign work to different nodes in the cluster. With a lot of parallelism, we can do slow transforms that may do IO to other services (like geocoding) and still get reasonable performance. It also gives us the ability to meet whatever service level we want by scaling the cluster up or down.
For a 28 million row dataset, running a simple string concatenation expression takes an amount of time proportional to the cluster size
| Cluster Size | Time spent evaluating |
|---|---|
| 1 node | 39.871s |
| 3 nodes | 17.539s |
| 5 nodes | 11.953s |
Results
We ended up with a system that handles the workloads we wanted with minimal drama. We’ve been running the system in production for several months now, and haven’t had issues that were related to our tools, which is about as much as you can ask for. One of the most impressive aspects of Elixir (and Erlang) is the tooling for analyzing a running system. We’ve shipped plenty of bugs out into production, but a combination of the Erlang Observer, the remote IEx repl, distributed tracing and debugging has allowed us to track them down quickly. These tools are indespensible, and once you have them, it’s exceedingly difficult to go back to a world without them.
Elixir as a language and Erlang as a platform has its pros and cons. Elixir is an extremely simple language, and our team was able to ramp up on it quickly. The tooling in the Elixir ecosystem is simple, well documented, and fits together well. Coming from a language like Java or Ruby, there will be some struggling to understand the Erlang/OTP programming model, but ultimately it simplifies fault tolerance, concurrency, and distribution into a small set of primitives which can be composed to make a reliable system. The language and VM are no silver bullet for reliability, but they encourage the developer to think about the common problems in building a distributed application.
One issue we ran into was that our team was used to the static typing provided by Scala, and leaving that behind has required some adjustment, for some more than others. This might be a non-starter for some teams, but may not be a big deal to others. It undeniably makes refactoring more difficult and requires that we have a more thorough test suite, which has a high overhead. We experimented with dialyzer, but found that it was too noisy to be usable.
Ultimately though, we’ve accomplished the goals we set out to accomplish, and more importantly we’re working at a pace which is sustainable. The most positive thing to say about Elixir and the tooling is that we don’t really think about it much. The amount of time we spend talking, thinking about, and wrestling with tooling (coming from a world of microservices) has been seriously reduced, which leaves much more time to focus on what actually matters, which building the product that our users use every day.
*Elixir is a language which compiles to Erlang AST and runs on the Erlang Virtual Machine, BEAM. Elixir has an identical programming model to Erlang, but with a different syntax, standard library, and tooling.